How does a neural network work? Implementation and 5 examples

Artificial neural networks can be considered as one of the popular subject areas in computer science. The reason behind that is their ability to perform critical artificial intelligence-related tasks such as image classification and recognition, credit card fraud detection, medical and disease recognition, etc.
What is a neural network?
Simply said, a neural network is a set of algorithms designed to recognize patterns or relationships in a given dataset. These deep neural networks are basically computing systems designed to mimic how the human brain analyzes and processes information.
A neural network consists of neurons interconnected like a web and these neurons are mathematical functions or models that do the computations required for classification according to a given set of rules. Through this tutorial, let’s discuss how these artificial neural networks work and their real-world usage.
How does a neural network learn?
Before moving on to learn how exactly the neural network works, you need to know what forms a neural network. A normal neural network consists of multiple layers called the input layer, output layer, and hidden layers. In each layer every node (neuron) is connected to all nodes (neurons) in the next layer with parameters called ‘weights’. .
Neural networks consist of nodes called perceptrons that do necessary calculations and detect features of neural networks. These perceptrons try to reduce the final cost error by adjusting the weights parameters. Moreover, a perceptron can be considered as a neural network with a single layer.
On the other hand, multilayer perceptrons are called deep neural networks. The perceptrons are activated when there is satisfiable input. Go through this wiki article if you need to learn more about perceptrons.
Now let’s move on to discuss the exact steps of a working neural network.
- Initially, the dataset should be fed into the input layer which will then flow to the hidden layer.
- The connections which exist between the two layers randomly assign weights to the input.
- A bias is added to each input. Bias is a constant which is used in the model to fit best for the given data.
- The weighted sum of all the inputs will be sent to a function that is used to decide the active status of a neuron by calculating the weighted sum and adding the bias. This function is called the activation function.
- The nodes that are required to fire for feature extraction are decided based on the output value of the activation function.
- The final output of the network is then compared to the required labeled data of our dataset to calculate the final cost error. The cost error is actually telling us how ‘bad’ our network is. Hence we want the error to be as smallest as we can.
- The weights are adjusted through backpropagation, which reduces the error. This backpropagation process can be considered as the central mechanism that neural networks learn. It basically fine-tunes the weights of the deep neural network in order to reduce the cost value.
In simple terms, what we do when training a neural network is usually calculating the loss (error value) of the model and checking if it is reduced or not. If the error is higher than the expected value, we have to update the model parameters, such as weights and bias values. We can use the model once the loss is lower than the expected error margin.
Neural network visualization
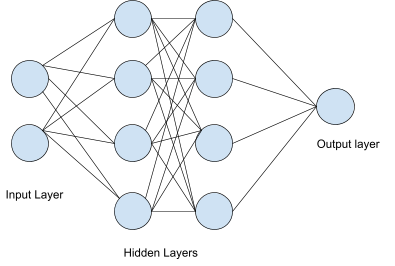
Neural networks can be described easily using the above diagram. The light blue circles represent the perceptrons we discussed earlier, and the lines represent connections between artificial neurons.
When considering one perceptron, its job can be visualized as follows.
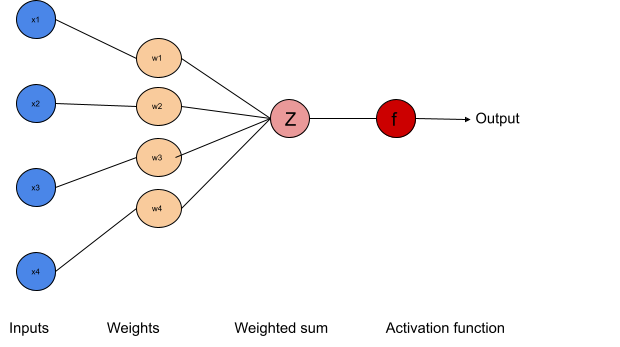
When you input the data with random weights to the model, it generates the weighted sum of them. According to that value, the activation function decides the activation status of the neuron. The output of this perceptron may act as an input for the next neuron layer.
Types of neural networks
There are a lot of types of neural networks that have been developed by now. The Convolutional Neural network (CNN) and Recurrent neural network (RNN) can be considered as two of the most prominent types of neural networks among them, which form the basis for most pre-trained models in neural networks.
Convolutional Neural Networks
CNN is a supervised learning model which consists of one or more convolutional layers. First those convolutional layers apply a convolutional function on the input. Then these layers are sent to the next layer. The neurons in a layer do not necessarily need to connect with the complete set of neurons in the next layer.
It connects only with a small portion of it. The resultant output is a single vector that includes the probability scores, which are then fed into fully connected layers. Convolutional Neural Networks are widely used in image recognition and natural language processing areas.
How does the bias works in Neural Networks
When working with Neural networks, it’s vital to understand what bias is and how it works. Bias can be considered as an additional set of weights in a model that doesn’t need any input, and related to the output of the model when it has no inputs. Adding a constant to the input bias allows to shift the activation function. There, a bias works exactly the same way it does in a linear equation:
y = mx + cHere the bias in c.
Bias is essential as it is always present without depending on the input and due to the fact that the network performs better with it.
Recurrent Neural Networks
RNN is a widely used neural network mostly used for speech recognition and natural language processing (NLP). It recognizes sequential characteristics of data and uses patterns to predict the following scenario. In RNN, the output of the previous step performs as the input to the next step.
RNN is distinguished by its “memory” since it obtains information from previous inputs to influence the current input and output.
Implementation of a neural network
By now, you should have a basic understanding of what a neural network is and how it works. Next, we are going to discuss how to implement a simple neural network. In this tutorial, we are using Python 3 for implementation since it contains quite famous and valuable libraries that support neural network-based implementations.
Handwritten number recognition is one of the easiest neural networks a beginner can develop. What we do there is, developing and training a neural network that predicts a specific image of a handwritten digit. The neural network type we are using here is Convolutional Neural Network (CNN). Here goes the code.
from numpy import mean
from numpy import std
from matplotlib import pyplot
from sklearn.model_selection import KFold
from keras.datasets import mnist
from keras.utils import to_categorical
from keras.layers import Conv2D
from keras.models import Sequential
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.optimizers import SGD
from keras.layers import Flatten
def loadDataset():
(train_X, train_Y), (test_X, test_Y) = mnist.load_data()
train_X = train_X.reshape((train_X.shape[0], 28, 28, 1))
test_X = test_X.reshape((test_X.shape[0], 28, 28, 1))
train_Y = to_categorical(train_Y)
test_Y = to_categorical(test_Y)
return train_X, train_Y, test_X, test_Y
def preprocess(trainSet, testSet):
train_norm = trainSet.astype('float32')
test_norm = testSet.astype('float32')
train_norm = train_norm / 255.0
test_norm = test_norm / 255.0
return train_norm, test_norm
def modelDefinition():
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1), kernel_initializer='he_uniform'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(100, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(10, activation='softmax'))
opt = SGD(lr=0.01, momentum=0.9)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
return model
def modelEvaluation(Xdata, Ydata, n_folds=5):
scores, histories = list(), list()
kfold = KFold(n_folds, random_state=1, shuffle=True)
for train_ix, test_ix in kfold.split(Xdata):
model = define_model()
train_X, train_Y, test_X, test_Y = Xdata[train_ix], Ydata[train_ix], Xdata[test_ix], Ydata[test_ix]
history = model.fit(train_X, train_Y, epochs=10, batch_size=32, validation_data=(test_X, test_Y), verbose=0)
_, acc = model.evaluate(test_X, test_Y, verbose=0)
print('> %.3f' % (acc * 100.0))
scores.append(acc)
histories.append(history)
return scores, histories
def summary(scores):
print('Accuracy: mean=%.3f' % (mean(scores)*100))
pyplot.boxplot(scores)
pyplot.show()
def runTest():
train_X, train_Y, test_X, test_Y = loadDataset()
train_X, test_X = preprocess(train_X, test_X)
scores, histories = modelEvaluation(train_X, train_Y)
summary(scores)
runTest()I have split the complete code into several functions so that it is easy to understand what each code segment does. We have used the famous and very useful Keras library that supports neural network development. So let’s consider each of these functions in the code and discuss what is done there.
loadDatset()This function mainly focuses on downloading required data and splitting the dataset into four datasets called tarinX, train_Y, test_X, and test_Y. Here, train_X consists of handwritten images that are used to train our model.
Train_Y is the label (actual digits of handwritten digits) of the images in the train_X dataset. Then we have test_X and test_Y. This test dataset is used to evaluate the system or to identify the accuracy of the developed model.
preprocess()This function is used to convert pixel values from integers to float and normalize the image in the 0-1 range. preprocess() returns this normalized image.
modelDefenition()This is the most important function we have written in this code. modelDefenition() function is used to generate our neural network. The activation functions that we have used here are ‘relu’ and ‘softmax.’
Other than that, there are several other activation functions that you can use in neural networks such as sigmoid function, leakyRelu, and tanh. You can gain proper knowledge of using these activation functions with Keras by reading this article.
The optimizer we have used in this model is ‘opt.’ Optimizers are used to change the attributes of the deep neural network to reduce the loss values.
Other than ‘opt,’ there are several other popular optimizers such as ‘adam optimizer’ and ‘RMSProp.’ You can use them according to the needs in your neural network. If you need to further learn about how to use optimizers in Keras you can read this page.
In Keras, you can visually see the summary of your model with the model.summary() function. Here is the result we got with our model.
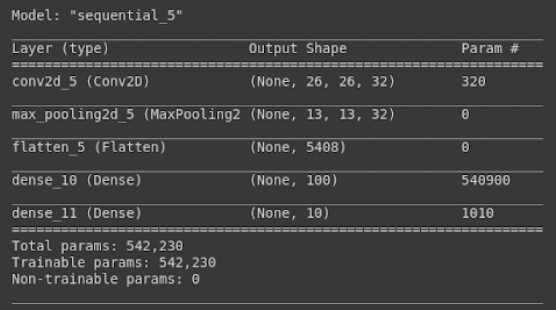
modelEvaluation()In this function, we have evaluated our model with ‘k-fold’ cross-validation. Cross-validation is a resampling procedure that is used to evaluate the neural network on a small data sample. There are several model evaluation methods such as leave-one-out cross-validation, leave-one-group-out cross-validation, and nested cross-validation.
When would you use a neural network?
This is a quite famous question for beginners most of the time. It is suitable to use a neural network when,
- The data which is required for the training purposes is sufficient.
- You have the required computational power.
- When you can’t find a clear relationship between data and resultant value.
Neural networks for the real world?
Actually, neural networks are very beneficial in solving many of the complex real-world issues such as:
- Stock exchange prediction
Making predictions on the stock exchange by using parameters, such as current trends, political situation, public view, and economists’ advice can be done with neural networks. For that, we can use neural networks such as convolutional neural networks and recurrent neural networks.
- Bank fraud detection
Bank fraud detection is one of the most important use cases of neural networks. There, you can provide a dataset that includes past bank fraud details. You can then detect and predict bank frauds by training the developed model with the given dataset.
- In recommendation systems
Recommendation systems are a very popular usage of neural networks. RNN is the type of neural network that is mostly used in recommendation systems.
- In searching platforms
Searching platforms such as Google and Yahoo also use advanced types of neural networks to improve their user experience. This significantly improves the usability of search engines.
Tesla car
Tesla is a company that highly makes use of neural networks in their products. The Tesla car is one of the very famous inventions of that company. It is an autopilot car that figures out the optimal route, manages complex intersections with traffic lights, and navigates urban streets while moving at high speed.
A complete build of Autopilot neural networks, which are used in the Tesla car, involves 48 networks that take 70,000 GPU training hours. Moreover, it outputs 1000 distinct predictions at each timestep.
The training datasets of the neural networks in the Tesla car contain the most complicated diverse scenarios in the world. These scenarios repeatedly sourced from the real-time fleet of nearly 1M vehicles.
This Autopilot car uses ultrasonic sensors, cameras and radar in order to sense and see the surroundings around the car. It uses neural networks to detect roads, cars, objects, and people in video feeds from eight cameras installed around the vehicle.
Conclusion
In this article, we discussed some important facts about neural networks such as what a neural network is, how it works, types of neural networks, and several use cases of it. Actually, neural networks can be considered as the most prominent research area in the field of computer science by now.
There are heaps of neural network models such as CNN and RNN. Tesla is one of the companies which heavily make use of neural networks. Their Tesla car, which is an auto-pilot car, has achieved massive success recently due to the better results gained through neural networks.
Neural network is an impressive technology that is responsible for tremendous breakthroughs in everything from facial recognition to traveling.
Subscribe to
our newsletter
Yay! You are now
subscribed to our
newsletter

Mize is the leading hotel booking optimization solution in the world. With over 170 partners using our fintech products, Mize creates new extra profit for the hotel booking industry using its fully automated proprietary technology and has generated hundreds of millions of dollars in revenue across its suite of products for its partners. Mize was founded in 2016 with its headquarters in Tel Aviv and offices worldwide.
Related Posts

6 Examples of How AI is Used in the Travel Industry
10 min. AI has made advances in many industries since it was invented. The ever-changing travel industry is also taking advantage of AI to revolutionize the way it operates. As a result, nowadays, travel companies highly leverage AI-powered tools and solutions for various processes from travel planning to landing in the destination. Here in this […]
This is the Difference Between Artificial Intelligence and Machine Learning
11 min. Are machine learning and artificial intelligence the same thing? The Fourth Industrial Revolution, or the new era of technology, is driving rapid advancements in the development of Artificial Intelligence and machine learning as a prominent part of its set of technological developments. Klaus Schwab, the founder and chief executive of the World Economic […]